AWS Blog In Collaboration With Nvidia — Optimizing Inference For Seq2Seq And Encoder Only Models…Posted on November 22, 2023 by Siddharth SharmaNov 22, 20232Nov 22, 20232
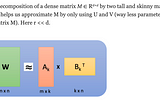
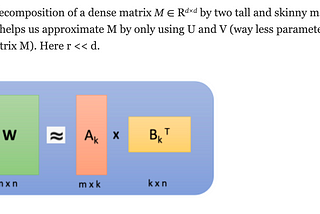
Compressing LLMs With Low Rank Decomposition Of Attention MatricesColab Link To Reproduce Experiment: LLM Compression Via Low Rank Decomposition.ipynbNov 22, 2023Nov 22, 2023
Summary Of Adapter Based Performance Efficient Fine Tuning (PEFT) Techniques For Large Language…The two most common transfer learning techniques in NLP were feature-based transfer (generating input text embedding from a pre-trained…Apr 21, 2023Apr 21, 2023
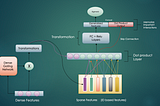
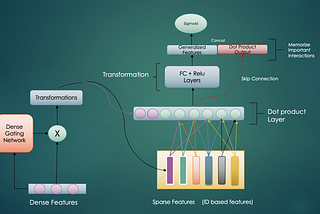
Neural Ranking ArchitecturesGlimpses On Implicit/Explicit, Dense/Sparse, Gated/Non Gated, Low Rank And Many More Layered InteractionsJan 19, 20232Jan 19, 20232
Feature Fusion For The UninitiatedConsider a typical e-commerce product. It would have a variety of content specific features like product title, brand, thumbnail etc and…Jan 13, 2023Jan 13, 2023
Of Bandits And BiddingReal-time bidding(RTB) refers to the buying and selling of online ad impressions through real-time auctions that occur in the time it takes…May 9, 20162May 9, 20162