Siddharth SharmaAWS Blog In Collaboration With Nvidia — Optimizing Inference For Seq2Seq And Encoder Only Models…Posted on November 22, 2023 by Siddharth Sharma1 min read·Nov 22, 2023----
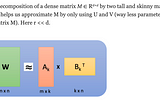
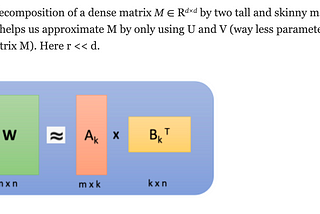
Siddharth SharmaCompressing LLMs With Low Rank Decomposition Of Attention MatricesColab Link To Reproduce Experiment: LLM Compression Via Low Rank Decomposition.ipynb5 min read·Nov 22, 2023----
Siddharth SharmaSummary Of Adapter Based Performance Efficient Fine Tuning (PEFT) Techniques For Large Language…The two most common transfer learning techniques in NLP were feature-based transfer (generating input text embedding from a pre-trained…5 min read·Apr 21, 2023----
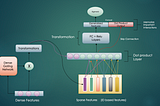
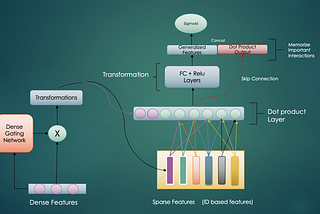
Siddharth SharmaNeural Ranking ArchitecturesGlimpses On Implicit/Explicit, Dense/Sparse, Gated/Non Gated, Low Rank And Many More Layered Interactions8 min read·Jan 19, 2023----
Siddharth SharmaFeature Fusion For The UninitiatedConsider a typical e-commerce product. It would have a variety of content specific features like product title, brand, thumbnail etc and…7 min read·Jan 13, 2023----
Siddharth SharmaOf Bandits And BiddingReal-time bidding(RTB) refers to the buying and selling of online ad impressions through real-time auctions that occur in the time it takes…14 min read·May 9, 2016--2--2